Ibland tar det stopp! Inga fler sökord ger det man vill ha. Prova då Inciteful! Utifrån en enda relevant artikel – det räcker med ett DOI-nummer eller titel – kan man hitta relaterade artiklar. Och få det visualiserat. Hur det funkar? Inciteful följer hur din artikel citerar och citeras i flera led och på olika sätt. Jättesmart – och den är gratis!
Jobbet tar ju inte slut när man väl publicerat sin forskning – då börjar nästa fas. Om allt går som man tänkt sig kommer din forskning att komma till användning. Litegrann beroende på vem du skriver för kommer din forskning att läsas och brukas av andra forskare, praktiker eller kanske rentav allmänheten.
Ett etablerat sätt att se vilka som använt sig av din forskning är att titta på vem som citerat den. När man gör det utgår man från en specifik citeringsdatabas och ser hur många som citerat publikationen.
Detta är ett system som har sina begränsningar. Det är lätt att tänka att enbart publikationer som har citeringar kommit till nytta. Men dels citeras publikationer av flera negativa anledningar (kontroversiella publikationer kan ha väldigt många citeringar), dels kan publikationer komma till användning på andra sätt än som citeringar i andra vetenskapliga publikationer.
Scite är en av flera AI-tjänster som underlättar för forskare att hitta och analysera artiklar*. En sak skiljer Scite från andra, liknande, AI-tjänster: de har en funktion som kategoriserar citeringar efter hur de används i en text, och de kan göra det i en toolbar som gör att du får upp informationen när du finner information om den.
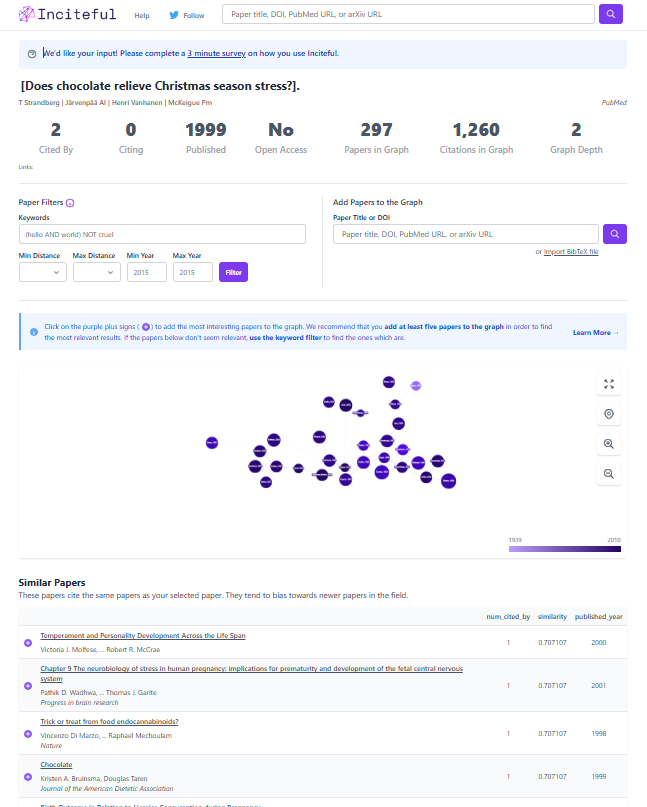
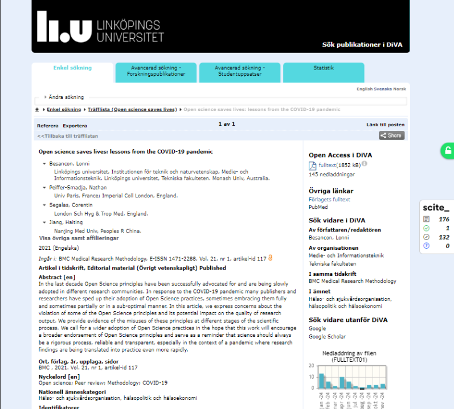
Ovan ser du en sida i DiVA, men det som är viktigt här är vad som dyker upp i högerkanten. Strunta i det gröna hänglåset (det har att göra med plugin till unpaywall) och fokusera på det som står om Scite. Artikeln av Besancon et al har enligt Scite 176 omnämnanden.
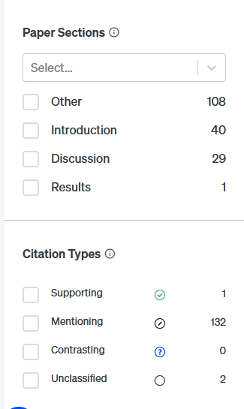
Klickar man på toolbar får vi lite mer information om omnämningarna. Vanligtvis omnämns inte artikeln i introduktion, diskussion eller resultat utan på andra ställen (vilket gör i alla fall mig nyfiken på var och hur den används) och som regel uttrycker den som använt studien varken sitt stöd eller sitt avstånd.
Vi får mer kött på benen, helt enkelt, och kan med hjälp av verktyget få en snabb indikation om hur artikeln tagits emot i forskarvärlden.
Kan vi lita på vad som står där? Tjänsten ger en indikation, men för att förstå behöver du som forskar in och läsa och göra din egen bedömning. Enligt Scite själva (https://help.scite.ai/en-us/article/how-are-citations-classified-1a9j78t/) bygger tjänsten på en databas av sk citation statements som kategoriseras med hjälp av en sk deep learning model.
Hur ser andra på vad du har skrivit? Håll med om att du är lite nyfiken nu!
Faktaruta: några spännande AI-verktyg
Det finns många AI-verktyg som underlättar att hitta och analyser publikationer. Använd dem med omdöme och dela inte med dig av för mycket information. Många AI-verktyg tillåter ett ental gratis-sökningar innan man behöver skapa ett login eller betala. Några av mina favoriter just nu: Elicit: https://elicit.com/ Perplexity: https://www.perplexity.ai/ Consensus: https://consensus.app/search/
Scopus AI är en följd av att alltfler akademiska sökverktyg gör just generativ AI mer tillgänglig för användarna. Min gissning är att AI funnits med i sökfunktionerna långt innan chatGPT landade i våra liv. Utöver Scopus har även Web of Science en variant vid namn Research Assistant.
Det går att använda Scopus AI med lite olika ingångar – men generellt gäller samma tänk som vid annan prompting: ju bättre prompt, desto bättre resultat och det är helt okej att successivt förbättra sin prompt. Det är nästan en förutsättning för att få ut något av sin sökning.
Ett exempel på användning
Jag är t ex intresserad över det tydliga motstånd som finns i att värdera en digital lärmiljö som något som kan vara en likvärdig motsvarighet till den fysiska. Hur uttrycker jag detta på ett bra sätt?
Prompt: The conversion of the physical learning environment to the digital learning spaces
Eftersom engelska inte är mitt modersmål och jag närmar mig ett område där jag inte riktigt lärt mig rätt typ av terminologi brukar det vara intressant att se över vilka nyckelord Scopus AI har skapat, baserat på min prompt. Fick jag det resultat jag hade tänkt mig? Skulle det vara bättre att använda andra begrepp?
Mycket handlar om COVID-19, är det relevant för mig? Referenserna som anges är relativt aktuella medan det som kallas Foundational documents har lite olika årtal – där spelar antalet citeringar större roll. Här saknar jag möjligheten att direkt utesluta resultat som inte är relevanta med hjälp av NOT och andra filter.
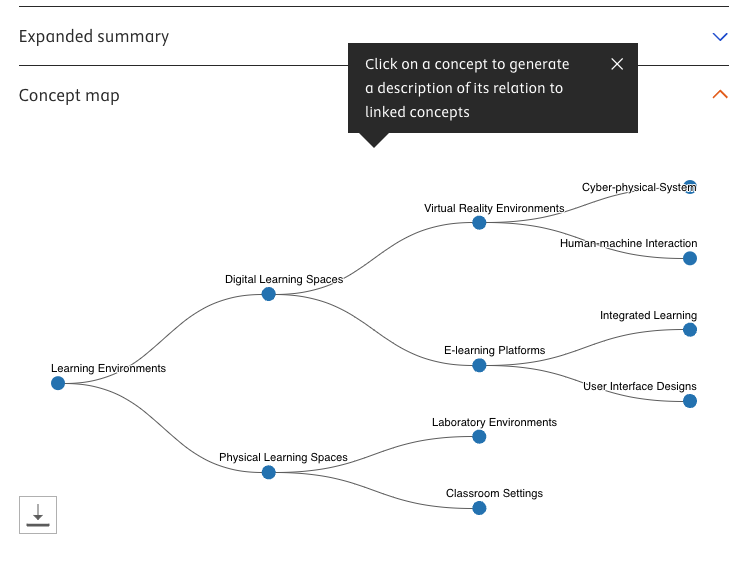
Sökresultatet som Scopus AI skapar ger dig möjlighet till en utökad sammanfattning (Expanded summary), en graf (Concept map), Topic experts – och en för mig ny rubrik: Emerging themes med symbolen “beta” bredvid rubriknamnet.
Concept map är också klickbar – du kan få en beskrivning av hur olika koncept hänger ihop. Och generera nya concept maps.
I slutet av sidan får du även förslag på följdfrågor där det t ex blir aktuellt att fundera över om det är “conversion” eller “transformation” jag är ute efter att undersöka. Vems perspektiv vill jag ta och vilka är de viktigaste skillnaderna mellan de olika lärmiljöerna? Det blir en slags idégenerering som sedan länkar vidare till potentiellt intressanta artiklar att läsa vidare i.
En viktig lärdom är att testa samma prompt lite då och då, för det är inte alltid du får samma sökresultat och glöm inte att spara det du hittar – gärna inklusive prompt inför arbete längre fram.
Har du liksom jag ägnat timmar, dagar eller kanske till och med år åt att försöka tyda en äldre handskrift?
Vi är många historiker, släkt- och hembygdsforskare som spenderat mycket tid på ”oläsbara” handskrifter i diverse arkiv. Med tanke på att 95% av allt arkivmaterial fortfarande inte är digitaliserat och inte heller kommer att bli det i närtid, så är tanken på att få hjälp att tyda handskrifter naturligtvis mycket lockande! Tänk dig en framtid när du sitter i forskarsalen på Landsarkivet i Vadstena och absolut inte kan tyda handskriften du har framför dig. Då tar du fram kameran, tar en högupplöst bild av texten, läser in den i ett program och vipps får du den transkriberad!
Den AI-baserade mjukvara, HTRflow (HTR=Handwritten text recognition), som Riksarkivet arbetar med, tränas att läsa och transkribera svensk handskriven text från 1600-1900-talen. Denna HTR-lösning har man nu släppt fri för andra att använda och hjälpa till att vidareutveckla.